papers
2024
-
 Towards Improved Multi-Source Attribution for Long-form Answer GenerationNilay Patel, Shivashankar Subramanian, Siddhant Garg, and 2 more authorsIn NAACL 2024
Towards Improved Multi-Source Attribution for Long-form Answer GenerationNilay Patel, Shivashankar Subramanian, Siddhant Garg, and 2 more authorsIn NAACL 2024Teaching large language models (LLMs) to generate text with attribution to evidence sources can reduce hallucinations, improve verifiability in question answering systems (QA), and increase reliability of retrieval augmented LLMs. Despite gaining increasing popularity for usage in QA systems and search engines, current LLMs struggle with attribution for long-form responses which require reasoning over multiple evidence sources. To address this, in this paper we aim to improve the attribution capability of LLMs for long-form answer generation to multiple sources, with multiple citations per sentence. However, data for training multisource attributable QA systems is difficult and expensive to annotate, and therefore scarce. To overcome this challenge, we transform existing QA datasets for this task (MULTIATTR), and empirically demonstrate, on a wide range of attribution benchmark datasets, that fine-tuning on MULTIATTR provides significant improvements over training only on the target QA domain. Lastly, to fill a gap in existing benchmarks, we present a multi-source attribution dataset containing multi-paragraph answers, POLITICITE, based on PolitiFact articles that discuss events closely related to implementation statuses of election promises.
@inproceedings{Patel2024, author = {Patel, Nilay and Subramanian, Shivashankar and Garg, Siddhant and Banerjee, Pratyay and Misra, Amita}, title = {Towards Improved Multi-Source Attribution for Long-form Answer Generation}, year = {2024}, url = {https://www.amazon.science/publications/towards-improved-multi-source-attribution-for-long-form-answer-generation}, booktitle = {NAACL}, }
2023
-
 A New Approach Towards AutoformalizationNilay Patel, Jeffrey Flanigan, and Rahul SahaarXiv preprint arXiv: 2328.7976 Dec 2023
A New Approach Towards AutoformalizationNilay Patel, Jeffrey Flanigan, and Rahul SahaarXiv preprint arXiv: 2328.7976 Dec 2023Verifying mathematical proofs is difficult, but can be automated with the assistance of a computer. Autoformalization is the task of automatically translating natural language mathematics into a formal language that can be verified by a program. This is a challenging task, and especially for higher-level mathematics found in research papers. Research paper mathematics requires large amounts of background and context. In this paper, we propose an avenue towards tackling autoformalization for research-level mathematics, by breaking the task into easier and more approachable subtasks: unlinked formalization (formalization with unlinked definitions and theorems), entity linking (linking to the proper theorems and definitions), and finally adjusting types so it passes the type checker. In addition, we present arXiv26Formal, a benchmark dataset for unlinked formalization consisting of 75 theorems formalized for the Lean theorem prover sampled from papers on arXiv.org. We welcome any contributions from the community to future versions of this dataset.
@article{patel2023new, title = {A New Approach Towards Autoformalization}, author = {Patel, Nilay and Flanigan, Jeffrey and Saha, Rahul}, year = {2023}, month = dec, journal = {arXiv preprint arXiv: 2328.7976}, } -
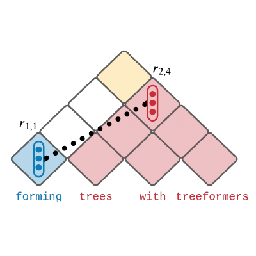 Forming Trees with TreeformersNilay Patel, and Jeffrey FlaniganIn Proceedings of the 14th International Conference on Recent Advances in Natural Language Processing Sep 2023
Forming Trees with TreeformersNilay Patel, and Jeffrey FlaniganIn Proceedings of the 14th International Conference on Recent Advances in Natural Language Processing Sep 2023Human language is known to exhibit a nested, hierarchical structure, allowing us to form complex sentences out of smaller pieces. However, many state-of-the-art neural networks models such as Transformers have no explicit hierarchical structure in their architecture—that is, they don’t have an inductive bias toward hierarchical structure. Additionally, Transformers are known to perform poorly on compositional generalization tasks which require such structures. In this paper, we introduce Treeformer, a general-purpose encoder module inspired by the CKY algorithm which learns a composition operator and pooling function to construct hierarchical encodings for phrases and sentences. Our extensive experiments demonstrate the benefits of incorporating hierarchical structure into the Transformer and show significant improvements in compositional generalization as well as in downstream tasks such as machine translation, abstractive summarization, and various natural language understanding tasks.
@inproceedings{patel-flanigan-2023-forming, title = {Forming Trees with Treeformers}, author = {Patel, Nilay and Flanigan, Jeffrey}, editor = {Mitkov, Ruslan and Angelova, Galia}, booktitle = {Proceedings of the 14th International Conference on Recent Advances in Natural Language Processing}, month = sep, year = {2023}, address = {Varna, Bulgaria}, publisher = {INCOMA Ltd., Shoumen, Bulgaria}, url = {https://aclanthology.org/2023.ranlp-1.90}, pages = {836--845}, }
2019
-
 Recommendation Algorithms for Student Evaluation DataNilay PatelJun 2019
Recommendation Algorithms for Student Evaluation DataNilay PatelJun 2019@article{patel2019recommendation, title = {Recommendation Algorithms for Student Evaluation Data}, author = {Patel, Nilay}, url = {http://purl.flvc.org/fsu/fd/FSU_libsubv3_scholarship_submission_1575654178_11be86508}, year = {2019}, month = jun }